Download and Decode Data
This system is designed to efficiently handle download raw data and decode data
Overview
Source code: https://github.com/untangledfinance/spark-crawler-decoder
Technical: Spark
Language: Scalar
Features:
- Data Ingestion: Download raw data from RPC services and save it to the data warehouse.
- Data Decoding: Decode raw data into call and event tables according to the provided ABI.
- Contract Information Retrieval: Fetch contract details (e.g., names, symbols, decimals of ERC20 tokens) from RPC services.
- Parallel Processing: Execute jobs on multiple nodes of an AWS EMR cluster for enhanced efficiency.
- Concurrent Data Handling: Download both historical and new data simultaneously.
- Automatic Decoding: Automatically decode data when new ABI information is added.
Execution
- Run by spark-submit on EMR cluster
- Controlled and scheduled by Scheduler: Airflow
Jobs in this system
Crawler: Job downloads data from RPC Service and stores it in the blocks table (raw transactions and logs data) and block_trace table (raw traces data)
ExtractLog: Extract log data from blocks table and save into logs table
ExtractTransaction: Extract transaction data from blocks table save into transactions table
ExtraceTrace: Extract trace data from block_traces table and save into trace table
DecodeLog: Decode log data in logs table and save into event table. Example: erc20_evt_transfer
DecodeTransaction: Decode trace data in traces table and save into call table. Example: centrifuge_shelf_call_borrow
GetContractInfo: Using RPC to get information of contract from event or call table and save into info table.
All job of this Application will be managed, scheduled in Airflow
Example for how to decode new datasets of protocol
Step 1: Determine contract address of protocol
- Using Dune as reference to find contract address
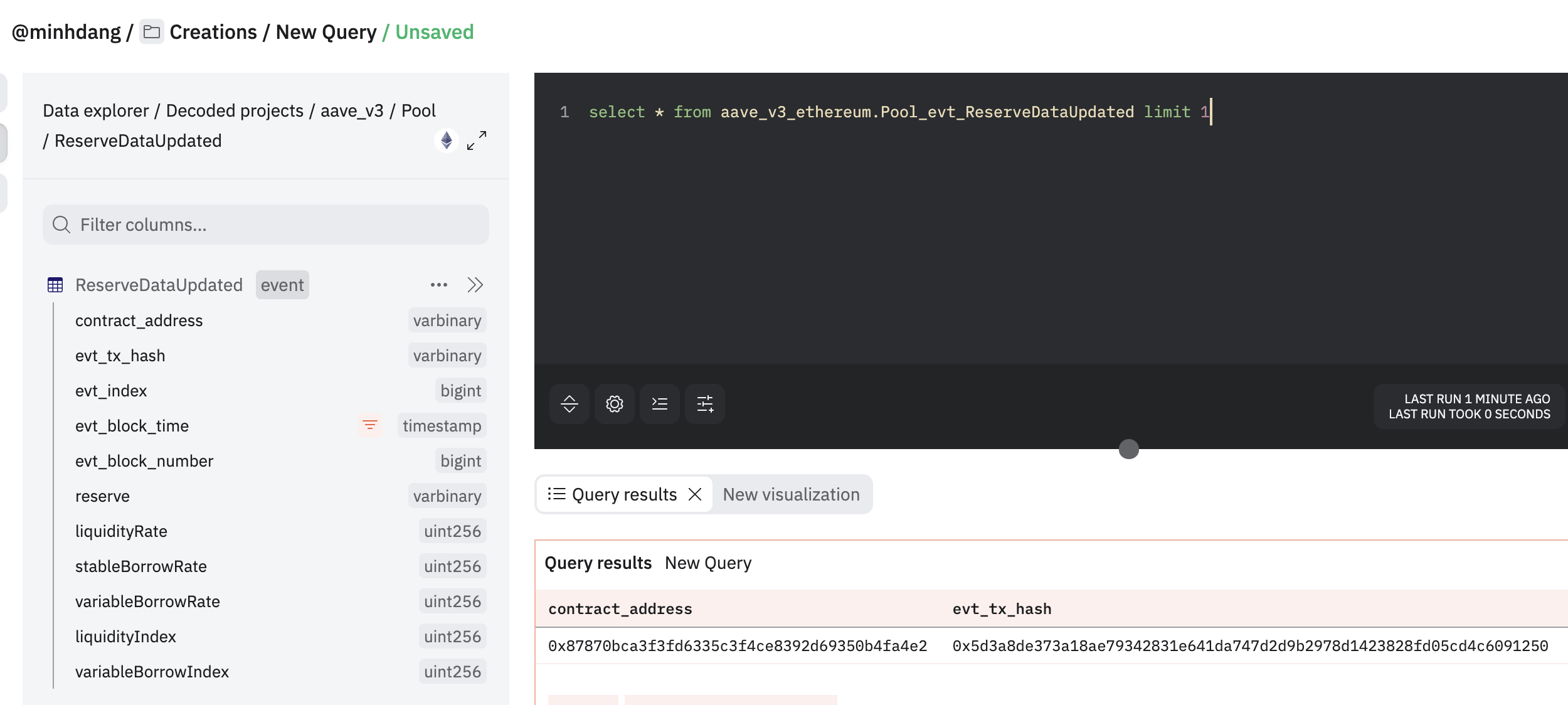
Step 2: From contract address of protocol, determine ABI of this contract
- Using https://etherscan.io/ to get ABI

Step 3: Open CMS, add protocols with ABI
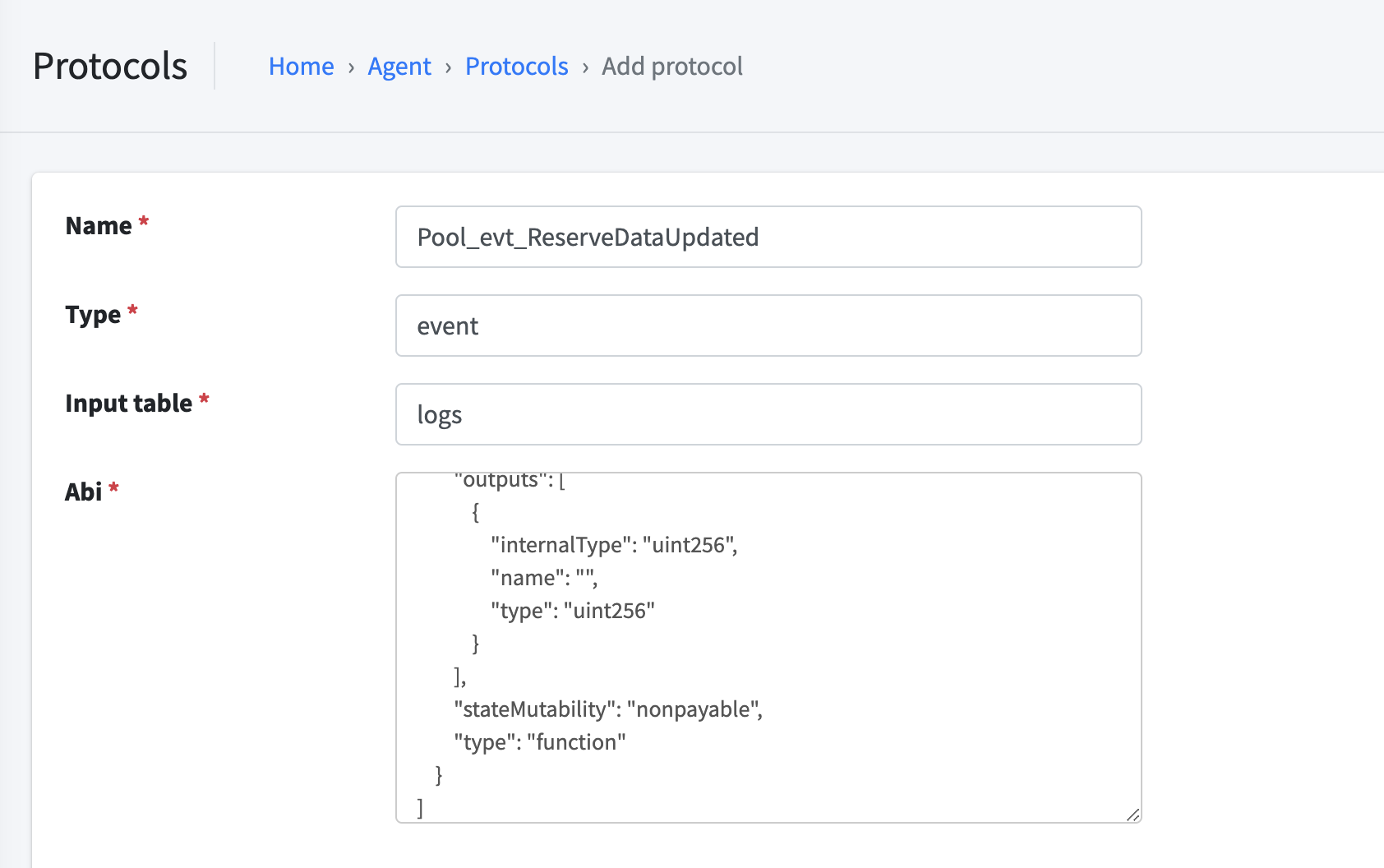
Step 4: Wait a minute and see new datasets in data warehouse